
Michael Wray
Assistant Professor of Computer Vision
I am a Senior Lecturer/Assistant Professor of Computer Vision at the School of Computer Science at the University of Bristol. My research interests are in multi-modal video understanding, particularly for egocentric videos — focusing on how both vision and language can be tied together towards tasks such as cross-modal retrieval, grounding and captioning. I am part of MaVi and ViLab. Short Bio.
Email: michael (dot) wray (at) bristol (dot) ac (dot) uk
News
- June 2026 - 2 Papers chosen for EgoVis Award Honoured that two of our papers: "Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives" and "HD-EPIC: A Highly Detailed Egocentric Dataset" were selected for the EgoVis Distinguised Paper Awards.
- May 2026 - Talk at ETH Zurich I gave a talk at ETH Zurich's Robotics, Vision, and Controls Talks (slides).
- May 2026 - BMVC 2026 Doctoral Consortium Chair I am honoured to be one of the Doctoral Consortium Co-Chairs for BMVC 2026, look soon for the call for participation!
- April 2026 - Paper Accepted at ICPR Congratulations to Shijia for the acceptance of "EvoStruggle: A Dataset Capturing the Evolution of Struggle across Activities and Skill Levels acc" at ICPR. Check out the paper and download the dataset!
- March 2026 - Area Chair for NeurIPS 2026 Honoured to be selected as an Area Chair for NeurIPS in 2026.
- March 2026 - Paper Accepted at CVPR Our Paper: "Beyond Caption-Based Queries for Video Moment Retrieval" was accepted at CVPR, congratulations to David! Find out more on the website/read the paper.
- January 2026 - New WACV Paper on ArXiv Out paper: "Towards Egocentric 3D Hand Pose Estimation in Unseen Domains" that will be presented at WACV 2026 is now on ArXiv.
- January 2026 - Area Chair for ECCV2026/ICML2026 Honoured to be selected as an Area Chair for both ECCV and ICML in 2026.
For a full list of News, click here.
Research
Short list of recent Research Projects, click here for a full list.
|
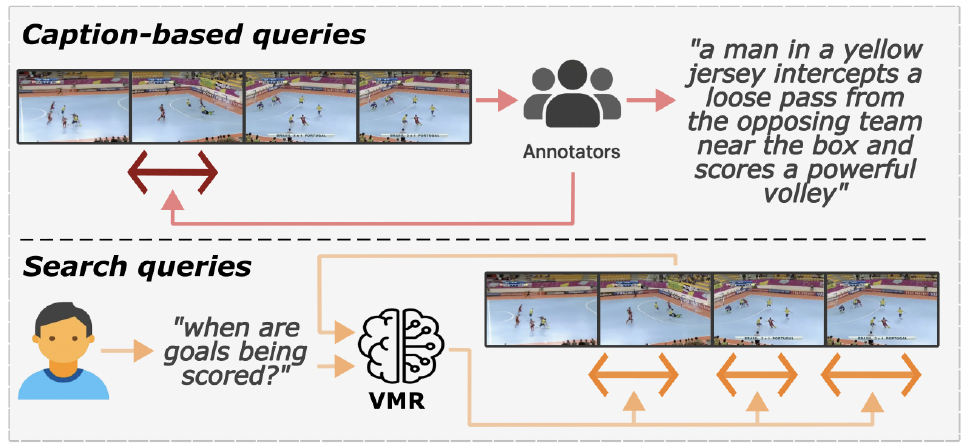
Beyond Caption-Based Queries for Video Moment Retrieval
David Pujol-Perich, Albert Clapés, Dima Damen, Sergio Escalera, Michael Wray CVPR, 2026 [Website] [arXiv] |
|
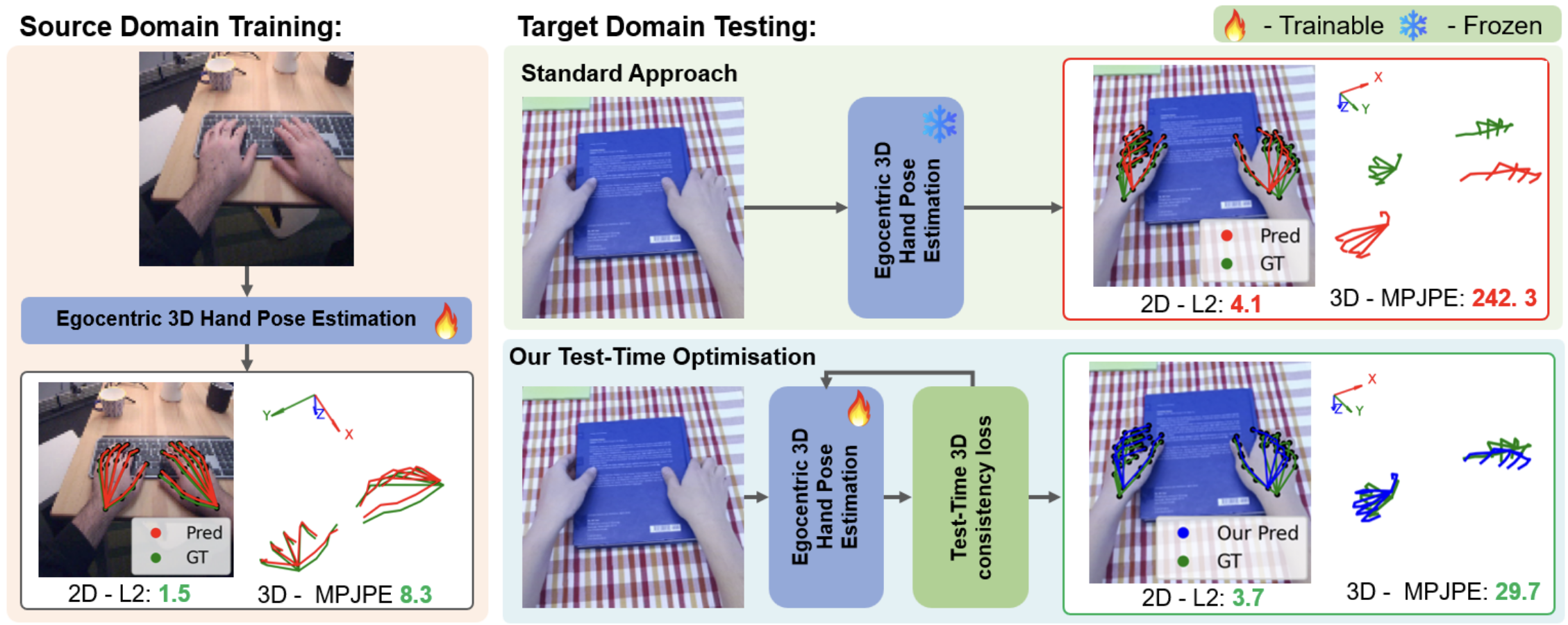
Towards Egocentric 3D Hand Pose Estimation in Unseen Domains
Wiktor Mucha, Michael Wray, Martin Kampel WACV, 2026 [arXiv] [code] |

|
From Detection to Anticipation: Online Understanding of Struggles across Various Tasks and Activities
Shijia Feng, Michael Wray, Walterio Mayol-Cuevas WACV, 2026 [arXiv] [code] |

|
A Video Is Not Worth a Thousand Words
Sam Pollard, Michael Wray ArXiv, 2025 [Website] [arXiv] [Code] |
|
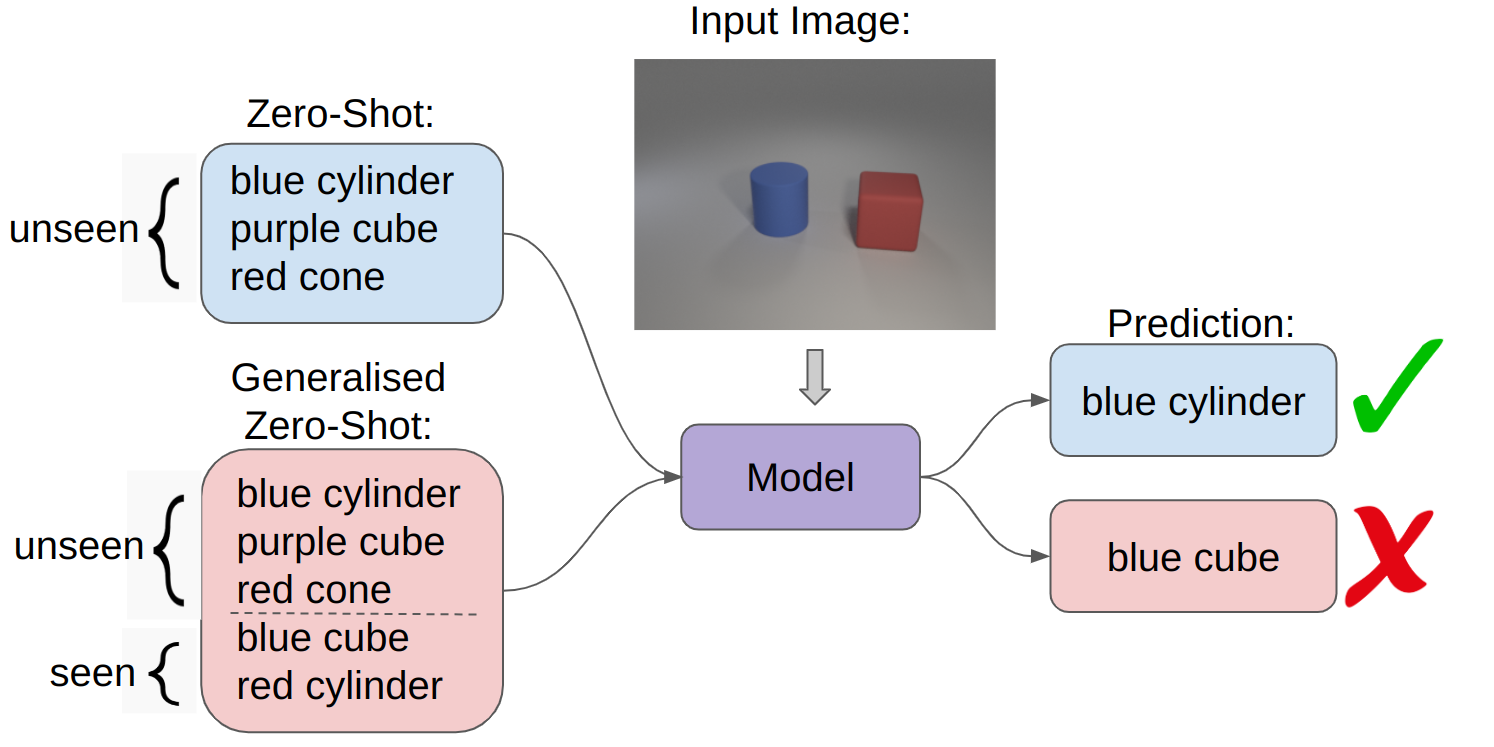
Evaluating Compositional Generalisation in VLMs and Diffusion Models
Beth Pearson, Bilal Boulbarss, Michael Wray, Martha Lewis *SEM, 2025 [arXiv] [Dataset] [Code] |
|
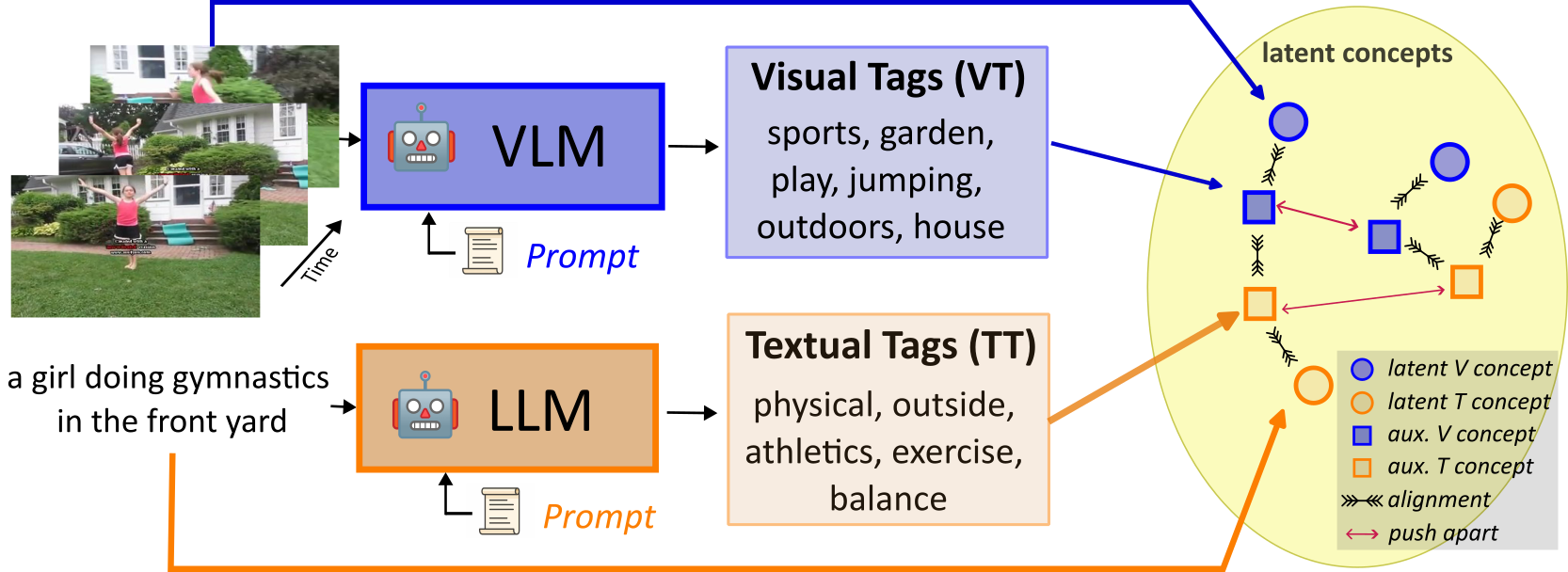
Leveraging Modality Tags for Enhanced Cross-Modal Video Retrieval
Adriano Fragomeni, Dima Damen, Michael Wray BMVC, 2025 [arXiv] |
For a full list of Research projects, click here.
Short Bio
Michael is a Senior Lecturer in Computer Vision at the School of Computer Science at the University of Bristol. He finished his PhD titled "Verbs and Me: an Investigation into Verbs as Labels for Action Recognition in Video Understanding" in 2019 under the supervision of Professor Dima Damen. After, he stayed in the same lab as a Post-Doc working on Vision and Language and the collection of the Ego4D Dataset. Michael has led the organisation EPIC workshop series from 2021 onwards, is an organiser of the Ego4D workshop series, and is an ELLIS member.Teaching
- Applied Deep Learning 22/23, 23/24, 24/25, 25/26. Webpage.
- Computer Systems A 22/23. 23/24, 24/25, 25/26. Webpage.
- Individual Projects 22/23. 23/24, 24/25. Webpage.
People
Current
- Rachael Laidlaw: PhD, 2025–Current
- Fahd Abdelazim: PhD, 2024–Current
- Sam Pollard: MEng, PhD, 2023–Current
- Beth Pearson: PhD, 2023–Current (w/ Martha Lewis)
Previous
- Shijia Feng: PhD, 2022–2025 (w/ Walterio Mayol Cuevas)
- Kevin Flanagan: PhD, 2021–2025 (w/ Dima Damen)
- Adriano Fragomeni: PhD, 2020–2025 (w/ Dima Damen)
- Josh Chatten: MEng, 2026
- Divit Kashyap: BSc, 2026 (w/ Andrew Calway)
- Kecen Li: BSc, 2026 (w/ Xiyue Zhang)
- Charlie Nasiadka: MEng, 2026
- Ava Raisian: BSc, 2026
- Clarissa Si-En Ch'Ng: BSc, 2026 (w/ Oussama Metatla)
- Sam Stephens: MEng, 2026 (w/ George Drayson)
- Alyssa Boisse: MEng, 2025
- Isabel Mendes Rodrigues: BSc, 2025
- Amr Khaled Mohamed El-Sawy: BSc, 2025
- Jacob Seaborn: MEng, 2025
- Aleksandra Walusiak: MEng, 2025
- Richa Banthia: MEng, 2024
- Alex Elwood: MEng, 2024 (w/ Tom Deakin)
- Moise Guran: MEng, 2024
- Rahat Mittal: BSc, 2024
- Bence Szarka: MEng, 2024
- Lee Tancock: MEng, 2023
- Zac Woodford: MEng, 2023
- Benjamin Gutierrez Serafin: MSc, 2020
- Pei Huang: MSc, 2016
Awards
EgoVis Distinguished Paper Awards
- HD-EPIC: A Highly Detailed Egocentric Dataset. 2024/2025 edition.
- Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives. 2024/2025 edition.
- Egocentric Video-Language Pretraining. 2022/2023 edition.
- Ego4D: Around the World in 3,000 Hours of Egocentric Video. 2022/2023 edition.
Best Paper Awards
- Ego4D: Around the World in 3,000 Hours of Egocentric Video. CVPR 2022 Runner Up.
- SEMBED: Semantic Embedding of Egocentric Action Videos. BMVA SS 2016 Honourable Mention.
Misc.
Doctoral Consortium Chair
- BMVC: 2026
Presentations
- ETH Zurich Why do Video Models Struggle on Real Data? 2026 (slides, video).
- BMVA Summer School Egocentric Vision Lecture 2025, 2024, 2023, 2022.
- VIViD Research Seminar, Durham University Fine Grained Video Understanding from a Personal Perspective. 2024.
- Advancements in Time Series Analysis for Computer Vision: Techniques, Applications, and Challenges Unlocking the Temporal Dimension from the Egocentric Perspective 2024.
- Video Understanding Symposium 2022 Do we still need Classification for Video Understanding? 2022.
- BMVA Symposium: Robotics Meets Semantics Towards an Unequivocal Representation of Actions. 2018.
- EPIC@ECCV2016 SEMBED: Semantic Embedding of Egocentric Action Videos. 2016.
Workshop Organiser
- WINVU@: CVPR2024
- EPIC@: ICCV2021, CVPR2021, ECCV2020
- Joint Ego4D+EPIC@: CVPR2023, CVPR2022
- Ego4D@: ECCV2022
Outstanding Area Chair
- CVPR2026
Area Chair
- CVPR: 2026, 2025, 2024, 2023
- ECCV: 2026, 2024
- ICML: 2026
- NeurIPS: 2026, 2025, 2024
Associate Editor
- IET Computer Vision 2024–Current
- ToMM Special Issue on Text-Multimedia Retrieval 2024
Outstanding Reviewer
- BMVC2024
- ECCV2022
- ICCV2021
- CVPR2021
- BMVC2020
Reviewing Duties
Conferences
- AAAI: 2026
- ACL-RR: 2026
- ACM-MM: 2026, 2025
- ACCV: 2024, 2022, 2020
- BMVC: 2025, 2024, 2023, 2022, 2021, 2020, 2019
- CVPR: 2022, 2021, 2020, 2019
- ECCV: 2022
- ICCV: 2025, 2023, 2021
- NeurIPS: 2023
- NeurIPS D&B Track: 2024, 2023
- WACV: 2027, 2026, 2024, 2023, 2022, 2021
Journals
- TPAMI
- IJCV
- TCSVT
- Pattern Recognition
- Machine Learning
- TOMM